AI 戰勝電競選手後,美國想用玩家腦波訓練軍事機器人

如同前陣子美軍使用無人機對伊朗行使斬首行動,證明現代戰爭即將進入自動時代,美國在軍事技術和思想一直走在世界最前端。
日前,稱為網路發源地的美國 DARPA(國防高等研究計劃署)開始了關於 AI 在軍事決策領域的研究。
用策略遊戲培訓 AI
從外媒報導,可得知紐約大學水牛城分校人工智慧學院工程師已獲得 DARPA 資助。他們透過創造類似《星海爭霸》或《恆星戰役》(Stellaris)等遊戲,並採集玩家的大腦活動和反應,使用這些資料訓練 AI 。
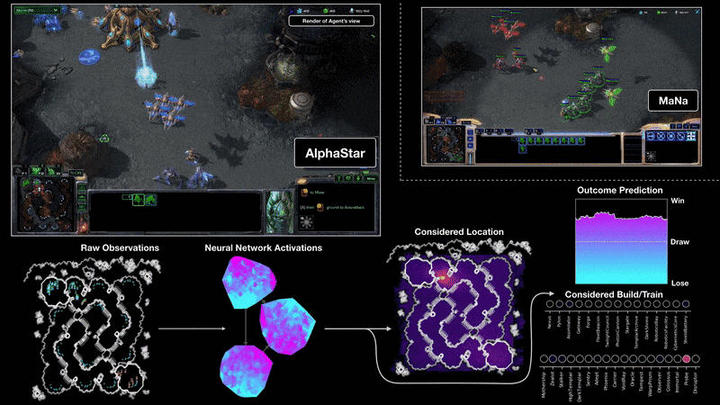
▲ DeepMind 決策過程。
與 AlphaGo 下圍棋不同,類似《星海爭霸》的 RTS 遊戲在策略和操作複雜度更高,需要玩家協調採集資源、建造建築、選擇進攻策略,甚至還要操控每個士兵的精細動作,且都是在有「戰爭迷霧」,也就是不完全資訊的條件下進行。

▲ 水牛城分校研究現場。(Source:水牛城分校)
很顯然,此類遊戲比簡單的棋類策略與真實的戰場環境更接近,在這種資訊不對稱的環境訓練的 AI,更容易在資訊錯綜複雜的戰場上做合理判斷。
監測腦波,向 AI 展示人類決策過程
可能有人要問,這和之前 Google 團隊針對《星海爭霸 II》開發的 DeepMind 有什麼區別。與 DeepMind 目的是獲勝不同,DARPA 想觀察人類在類似場景的判斷和決策,並用機器學習演算法整理,訓練出能相互協調的機器人。
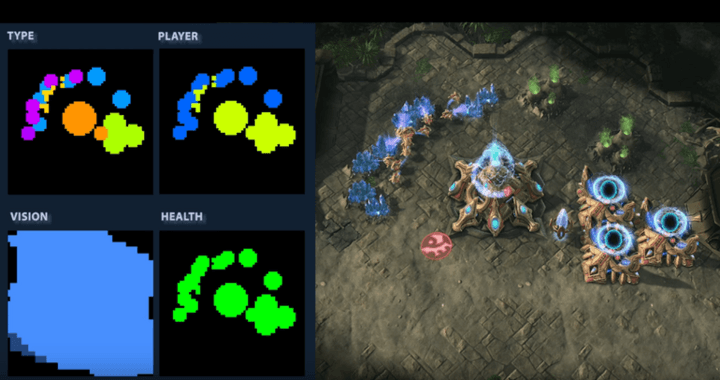
▲ DeepMind 眼中的遊戲。
為了達成目的,DARPA 要求所有在水牛城分校玩新策略遊戲的玩家配戴偵測腦波圖(EEG)的頭盔。觀察玩家做決策時,研究者可對照腦波圖,觀察玩家在策略選擇時的大腦活動。
同時研究人員還搭配特殊的超高速鏡頭追蹤玩家的眼球運動。配合遊戲畫面,觀察人類在決策時的直覺反應。
為什麼 DARPA 要做這研究?
對於 DARPA 來說,他們並不想要單單執行工作的機器人,他們需要一群機器人互相配合,根據目前掌握的資訊自己規劃、並有策略的完成工作。
如果策略執行時遇到阻礙,也能隨機應變。比如高度複雜的環境下(天氣、地理環境、敵我動態)多達 250 個單位(空中與地面機器人)協作,這時突然出現煙霧導致可見度低落,AI 控制的機器人同樣能改變策略,完成工作。

▲ 未來的無人機蜂群作戰。
只有達到這種程度,AI 在軍事領域的應用才能派上用場。
但從目前來看,目前 AI 都是在相對確定的環境下訓練,但真實環境往往複雜且缺乏資訊。在這種環境下決策,AI 需要根據已知資訊推理,目前 AI 在這方面還處於新生兒狀態。

▲ 美軍微型無人機「蜂群」展示。(Source:影片截圖)
此研究的意義是讓人類成為老師,向 AI 展現人類長期演化後的直覺,並透過監測腦波,向 AI 展示人類如何處理接收的資訊,進而讓 AI 產生推理能力,並最終學會如何制定總體策略。

▲ 完成工作後「蜂群」繞圈飛行。(Source:影片截圖)
我們知道,人類之所以能生存下來,就是因為人類不僅有個體決策,還有指導人類完成工作的總體策略。所以如果想要 AI 完成人類的工作,指導 AI 相互配合並制定總體決策就勢在必行。
結語
過去,機器是輔助人類工作的工具,必須由人操控。後來,人類為工具編好執行流程,讓工具按照流程自動工作。
現在,機器透過機器學習和神經網路演算法,能執行簡單的判斷和決策工作。
未來,人類將賦予機器群體策略能力,人類不再需要為每個機器決定工作,我們只需要給一個目標,AI 就會制定整體策略,並分配工作給獨立 AI 操控的每台機器,合作完成任務。
從總體來看,這是人類的一大技術進步。只是從歷史角度看,這種技術通常先用在軍事行動。還是那句老話:技術不分善惡,只在用途。如果這種技術成為現實,希望永遠不要用於戰爭。
延伸閱讀:
Measure
Measure