万字深度好文!视觉-语言(VL)智能:任务、表征学习和大型模型
导语:本文对视觉-语言(VL)智能按时间顺序进行了全面调研。

编译丨Jocelyn
编辑丨陈彩娴
本文对视觉-语言(VL)智能按时间顺序进行了全面调研,并将这一领域的发展总结为三个阶段:
第一个阶段是2014-2018年,其间,专门的模型被设计用于不同的任务。第二个时代是2019-2021年,在此期间,通过使用有着高质量标签的VL数据集进行预训练,神经网络模型能够学习视觉和语言的联合表征。最后,随着2021年CLIP的出现,第三个时代开始了,此时研究人员寻求在更大的弱标签数据集上预训练VL模型,并通过VL预训练获得性能强大的基于零样本或少样本的视觉模型。
我们相信这篇综述将有助于人工智能(AI)和机器学习(ML)的研究人员和实践者,特别是那些对计算机视觉和自然语言处理感兴趣的人。

论文地址:https://arxiv.org/pdf/2203.01922.pdf
1
研究背景
计算机视觉(CV)和自然语言处理(NLP)是人工智能的两大分支,它们专注于在视觉和语言上模拟人类智能。在过去的十年中,深度学习极大地推进了单模态学习在这两个领域的发展,并在一系列任务上取得了先进的成果。深度学习显著进步的核心在于GPU的快速发展和大规模数据集的可用出现,这些加速了深度学习模型的大规模训练。
随着深度学习的发展,我们也看到了一系列功能强大的神经网络的发展。传统的神经网络通常是由多层线性层和非线性激活组成的多层感知器(MLP)。LeCun等人于1998提出了卷积神经网络(CNN),将平移不变性作为对2D视觉输入的更好的归纳偏差,这启发了大量的深度神经网络,包括AlexNet,VGGNet, GoogleNet和ResNet。
另一个主要的突破是自然语言处理(NLP)领域的循环神经网络(RNN),它提出了循环神经元用于序列数据建模。为了缓解长序列训练中的梯度消失和梯度爆炸问题,LSTM(RNN的一种变体)和GRU(LSTM的一种更高效的版本)被提出。NLP的另一个重大突破是Transformer,它利用注意力机制追求更好的语言表征。使用多个堆叠的注意力层,Transformer可以以高并行性在全局范围内融合语言符号的信息,这有利于有效的表征和大规模的训练。
虽然我们在单模态领域技术取得了鼓舞人心的进展,但现实世界的问题往往是涉及多模态的。例如,自动驾驶汽车应该做到能够处理人类的命令(语言)、交通信号(视觉)、道路状况(视觉和声音)。即便单模态学习也能从多模态学习中受益。例如,语言学习需要感知,而感知是许多语义公理的基础。
感知是人类理解物质世界的方式,决定了人类语言背后的意义。由于我们听到和看到的是同样的事情,一些知识便被留下来作为常识,这些常识在我们的语言中是没有记录的。即便仅仅在语言领域,演讲也比纯文本包含更多有用的信息,例如,韵律可以暗示情感。
多模态感知在多模态和单模态任务中都有帮助,因此诞生了大量的相关研究工作。在多模态领域中,由于视觉是人类用于理解环境最重要的感官之一,并且语言-视觉特征结合能够极大地改善视觉和视觉-语言任务的表现,在视觉-语言集成的相关研究获得到许多的关注。此外,视觉语言智能的普及还得益于该领域丰富的数据集和评估标准。
解决特定任务VL问题的雄心推动了VL学习的初步发展。这些VL问题包括图像字幕、视觉问答(VQA)、图像-文本匹配等。Xu一些人于2015年的工作集成了一个CNN图像编码器和一个RNN文本解码器用于图像说明。Antol等人于2016年通过将图像和文本映射到相同的潜在空间并从潜在表征中预测答案来解决VQA任务。Lee等人于2018年通过计算图像和文本在句子级别或标记级别上的相似度来进行图像-文本匹配。这些模型是为各种数据集的特定问题量身定制的,其中每个模型只能解决一个任务。
受语言和视觉的预训练和微调的流行启发,视觉和语言的跨学科领域迎来了一个新时代: 通过图像-文本对的预训练来学习视觉和语言的联合表征。VLP模型的兴起主要是受到了架构设计和训练方法中语言模型的启发。例如,最近的许多研究采用了与BERT相似的架构和训练方法。由于缺乏足够大规模的人工标注数据,VL学习的发展面临着严峻的挑战。最近,一些研究通过采用对比学习和利用大规模网络爬虫爬取数据学习视觉语言特征而打破了这一限制,它们所获得的特征可用于零样本学习。
随着VL领域的快速发展,目前亟需一个对该领域现有研究的全面调研。本文旨在提供一个结构化的、关于VL领域的最新进展的综述,以帮助研究人员获得一个整体的VL领域的情况,并更好地理解最新的研究成果。
我们将VL学习的发展分为三个阶段。第一个是从2014-2018年,其间,专门的模型被设计用于不同的任务。第二个时代是2019-2021年,在此期间,通过使用有着高质量标签的VL数据集进行预训练,神经网络模型能够学习视觉和语言的联合表征。最后,随着2021年CLIP的出现,第三个时代开始了,此时研究人员寻求在更大的弱标签数据集上预训练VL模型,并通过VL预训练获得性能强大的基于零样本或少样本的视觉模型。
回顾VL智能的整个发展过程,我们发现其总体目标是学习良好的视觉特征。一个好的视觉特征应该具有三个属性,即对象级别、语言对齐和语义丰富。对象级别意味着视觉和语言特征的细粒度应该分别与对象级别和单词级别中的保持一致。语言对齐强调的是与语言对齐的视觉特征可以帮助完成视觉任务。语义丰富是指不受领域限制地从大规模数据中学习特征。
在VL的第一个时代,相关科学研究工作的目的是解决具体的问题,而不是学习上述良好的特征。在第二个时代,研究人员基于图像-文本对来训练模型,以获得语言对齐的视觉特征。这个时代的一些研究成果采用检测到的区域作为图像特征,从而学习对象级别的特征。只有在第三个时代,研究人员才能处理大规模的数据集并使用蕴含丰富语义信息的特征来预训练。
2
特定任务问题
早期的 VL 方法是针对特定任务设计的。VL领域包含广泛任务,包括图像说明,视觉问答,图文匹配,视觉对话等。
本节中,我们详细介绍三个最常见的任务:图像说明、视觉问答和图文匹配。我们总结了特定任务方法的发展是从全局表征到细粒度的以对象为中心的表征。
大多数VL任务有三个阶段,包括全局向量表征和简单融合;网格特征表征和跨模态注意力机制和以对象为中心的特征表征和自底向上自顶向下的attention。这三个阶段的代表工作如图1所示。
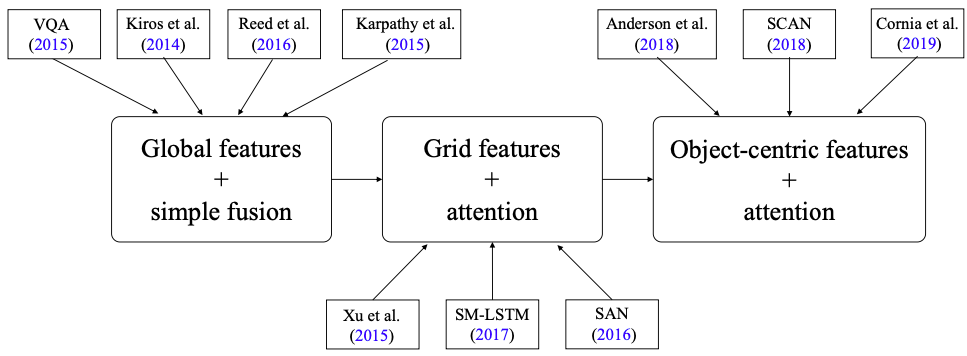
图1所示,这三个阶段的任务具体方法。主要区别在于视觉representation的粒度和视觉与语言特征融合的方式。
A 图像说明
任务定义: 图像说明的目标是为给定的图像生成“标题”,即用一句话总结图像内容。标题通常包含感兴趣的对象、对象的行为以及对象之间的位置关系。
方法: 深度学习出现之前,早期图像说明方法主要基于规则。它们首先识别对象及其关系,然后根据预定义的规则生成标题。这种早期的方法由于视觉识别器词汇量有限以及基于规则的方法在处理人类语言中复杂场景的局限性的原因而效果有限。
深度学习技术的突破极大地增强了图像说明功能。Seq2Seq在机器翻译方面取得了巨大的成功,它利用文本编码器对源语言的文本进行编码,利用文本解码器从目标语言生成文本。
在Seq2Seq的编码器-解码器结构的基础上,Xu等人提出用GoogleNet的图像编码器替代文本编码器,并取得了当时最前沿的性能。于是这种编码-解码的结构开始流行起来,并被后续的工作广泛采用。这个结构称为img2seq,如图2所示。
早期研究采用CNN模型作为图像编码器进行提取一种全局的CNN特性,将其作为初始隐藏状态输入文本解码器。m-RNN和LRCN提出将全局CNN特征添加到LSTM解码器的每一步。
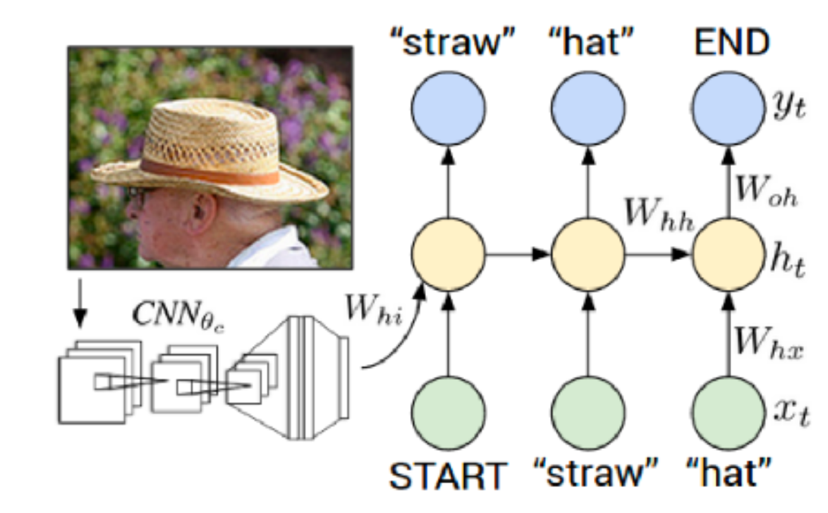
图2所示,img2seq结构包含图像编码器(如CNN)和语言解码器(如LSTM)。
全局CNN特征有一个明显的弱点,因为解码器不能像人类那样聚焦于图像的重要区域。为解决这个问题,引入了注意机制。
Xu等人于2015年提出了一种将注意力机制引入特征的方法。假设CNN特征提取器的输出特征图形状为(H, W, C),其中H, W为特征图的高度和宽度,C为特征维数。feature map可以沿空间维度扁平化为H × W的C个纬度的网格特征。对于LSTM解码器的每个cell,隐藏状态都要关注网格特征,以决定关注哪个网格。
与卷积相比,注意机制具有以下优点。它通过对重要的网格特征给予更高的attention权重,使模型能够聚焦于图像的某些部分。此外,该模型能够学习与人类直觉高度相似的对齐方式。模型的可解释性也可以通过可视化的attention分数得到改善,这样可能有助于排除网络错误。
然而,将一幅图像分割成大小相同的网格只是一种执行attention的朴素方法,因为网格与对象的对应关系很差。为了解决这个问题,一些研究人员试图将注意力与更有意义的区域联系起来。
Anderson等人(2018)提出了一种自底向上和自顶向下的注意力方法(BUTD),将注意力与检测模型获得的显著区域进行对应。BUTD使用在视觉基因组上预训练的Faster-RCNN模型提取区域特征。由于检测到的对象区域通常包含有意义的视觉概念,且能够与人类语言更好地匹配,因此BUTD显著提高了图像说明和VQA的性能。因此,预训练的检测器在后续的VL研究中被广泛采用。
注意力机制运用的方式也有一些不同。例如,Lu等认为因为有些单词与视觉特征无关,解码器不需要一直保持关注视觉特征。因此,他们提议用一个门来决定注意力机制是否参与其中。AoA设计了一个特殊的“注意力叠加机制”的图像说明任务。在标准注意力机制之后,它们将被关注的向量和query连接起来。然后由串联向量生成信息向量和注意门,将信息向量与信息向量相乘得到输出。
除上述工作,也有不运用注意力机制的工作。例如,Neural Baby Talk首先生成一个句子模板,然后用图像中检测到的概念填充它。Cornia等人通过预测名词块的序列来生成一个句子。它们首先检测区域,然后使用排序网络对区域进行排序。最后,每个区域将被转换成一个名词块来组成句子。
综上所述,早期图像说明方法的发展主要有两个方面,即视觉表征和语言解码。视觉表征从图像级的全局特征发展到细粒度和对象级的区域特征,语言解码从LSTM发展到基于注意力机制的模型。
B. 视觉问答
任务定义: 给定一个图像-问题对,视觉问答要求根据图像回答一个问题。大多数研究都将视觉问答视为一个基于预定义答案集的分类问题。例如,VQA v2 有大约2K个预定义答案。
方法: 普遍的视觉问答是LSTM问题编码器和VGG图像编码器的组合。输出图像潜入和问题嵌入,它们通过逐点相乘来简单地进行融合。然后,融合向量经过一个线性层和一个Softmax层,输出选择每个候选答案的概率。模型的体系结构如图3所示。视觉问答中的后续研究通常采用相同的方法原型。
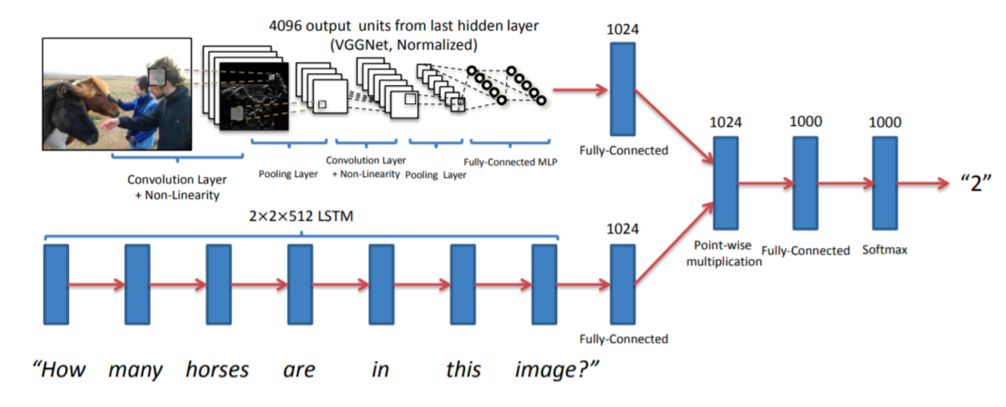
图3所示。vanilla VQA的体系结构包含一个CNN模型来编码输入图像和一个LSTM模型来编码输入问题。将编码后的图像和问题特征进行点积合并,然后通过全连通层来预测候选答案的概率。
早期研究通常采用全局图像表征和简单融合的方式。Malinowski等于2015提出将CNN图像特征输入到问题编码器的每个LSTM 单元中。同年,Gao等使用了一个共享的LSTM来编码问题和解码答案。他们将CNN图像特征与每个解码器单元的输出融合,逐字生成答案。
问题回答通常只与图像的某些区域有关。因此,由于不相关区域带来的噪声,全局表征只会导致次优解。Yang 等人于2016年提出了堆叠注意网络(stacking Attention Network, SAN)将多个问题引导的注意层堆叠起来。在每一层中,问题的语义表示被用作对图像网格的查询。SAN是是一个验证视觉问答中注意力有效性的工作。Fukui等人同样采用了网格特征,他们通过双线性池化融合图像和语言特征。
正如我们在图像说明任务中所说,网格特征具有它的局限性。针对这个问题,Shih等人提出使用边缘框定位出的区域特征作为视觉表征。BUTD预训练了一个强大的检测器,并使用问题特征作为queries来关注区域特征。Lu等人认为对文字的关注与对图像的关注同等重要。因此,他们开发了一种联合执行文本引导的图像注意力和图像引导的文本注意力的共注意力方式。
除注意力以外,还有其他的模态融合策略。Ren等人将图像特征视为语言标记。它们将图像嵌入与语言标记连接起来作为LSTM的输入。Kim等人提出了一种用于模态融合的元素乘法迭代方法,名为多模态残差网络。MUTAN提出了模式间参数化的双线性相互作用。虽然融合图像和语言特征的方法有很多,但注意力机制依旧是最常用的一种。
图像问答的核心是获取图像和语言(问题)的联合表征。该领域的研究人员通过多种方式来更好地编码和融合图像与语言,为后续的视觉学习表征VLP方法奠定了基础。该领域大多数工作都是将图像和语言独立编码,然后进行融合,这类似于视觉学习表征VLP中的双流方法。Ren等人将图像嵌入视为一种语言标记,类似于单流方法。
C.图文匹配
任务定义: 图像-文本匹配 (ITM),或说图文检索,是视觉领域的基本课题之一。给定一个特定模态 (视觉或语言) 的query ,它的目标是从另一个模态中找到语义上最接近的目标。根据query和目标模式,它包含两个子任务: 图像-文本检索和文本-图像检索。
方法: 图像-文本匹配的核心是计算图像与文本之间的相似度或距离。一个被广泛采用的模型是将图像和文本映射到共享的嵌入空间,然后计算它们的相似性。所匹配出的图像结果预期与句子的相似度最高。
早期方法主要采用全局特征对图文信息进行编码。Kiros等提出了一种基于铰链的三联体排序损失的交叉视图表示方法。Faghri等人考虑硬负样本因素来提高性能。Karpathy等人提出“深度片段” (Deep Fragment),这是首次尝试在图像端和文本端都使用细粒度表示的方法。
“Deep Fragment”的体系结构如图4所示。与直接表示整个图像和句子不同,该方法将每个图像片段和句子片段映射到跨模态嵌入空间中。然后于不同模式之间排列片段。由于一个图像区域可能与多个单词相关,他们会为每个单词的嵌入找到最相似的区域。图像与句子的相似度是对齐后的词对与区域对的相似度之和。
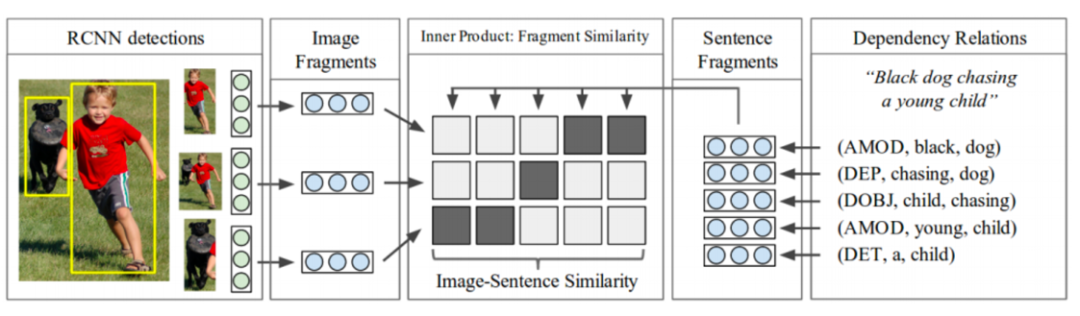
图4所示。Deep fragment结构概述。左:将检测到的对象映射到片段嵌入空间。右:依赖树关系被编码为片段嵌入空间。
由于注意力机制在其他视觉学习任务中取得了巨大成功,Huang等2016年提出将注意力机制引入到图文匹配(ITM)中。他们开发了一种上下文调节的注意力方案,以关注出现在图像和文本中的实例对。Nam等2017年提出了一种双注意力框架,该框架通过多个步骤来关注图像和文本中的特定区域,并从这两种模态中收集重要信息。
这些方法证明了注意力机制在ITM任务中的有效性。但是它们也存在局限性,比如它们是基于多步骤的方法,并且一次只能关注一个语义部分。Lee等人于2018提出了一种名为SCAN的交叉注意力算法,用于计算图像和句子之间的相似性。为实现交叉注意力机制,它们将图像表示为一组区域,将句子表示为一组单词。交叉注意的核心思想是,既要用句子作为query来关注图像区域,也要用图像作为query来关注单词。
简单来说,图文匹配本质上是计算图像和文本之间的相似度的问题。早期研究将图像和文本编码成全局特征,并通过点积计算它们的余弦相似度。在随后的工作中,采用了细粒度特征-目标级特征来代表图像,单词级特征来代表语言。他们还开发了更复杂的算法来计算相似性,比如交叉注意力的方法。
D.其他任务
在视觉-语言跨学科领域中,有许多我们无法详细阐述的任务。因此,我们下面简单中列出了一些重要的任务,包括:
文本-图像生成: 给定一段文本,生成包含该文本内容的图像。关于这部分更多细节请查看文章的IV-B部分。
视觉对话: 给定一个图像,一段对话历史,和一个关于图像的问题,回答这个问题。
视觉推理: 与要求回答有关输入图像问题的VQA任务类似,视觉推理要求进一步理解图像的能力。视觉推理任务通常包含足够的关于图像中的对象、问题结构等的注释。
视觉蕴涵: 给定一幅图像和一篇文本,判断该图像在语义上是否包含输入文本。
短语基础和参考表达式理解: 这两个任务需要一个模型来输出与文本对应的边界框。对短语基础而言,文本是一组短语; 对于引用表达理解而言,文本是一种表达。
在特定任务方法的时代,研究人员为不同的任务设计了特定的模型。尽管不同任务的模型差异很大,但它们遵循着相似的轨迹。它们都有三个阶段,如图1所示。这个时代的技术发展为VLP时代奠定了基础。
3
视觉语言联合表征
预训练和微调范式已被广泛应用于多个领域和各种下游任务。利用流行的大规模预训练最重要的原因在于大量可用的数据集以及GPU的快速发展。在单模态的语言/视觉预训练成功的推动下,研究人员开始探索语言和视觉的联合表征,因此提出了跨模态VLP模型。
近年来VLP模型的兴起主要是受到了语言模型中架构设计和训练方法的启发。其中最重要的突破之一是由Vaswani等人于2017开发的用于改善语言表征的Transformer。使用多个堆叠的注意层,Transformer可以以高并行性在全局范围内融合语言标记上的信息,这有利于高效的表征和大规模的训练。
Transformer的一个成功应用是BERT,它利用Transformer编码器并引入了双向屏蔽技术,允许每个语言标记双向关注其他标记。如图5所示,训练是通过用一个特殊的[MASK]标记(即掩模)替换一些文本标记来进行的,并使用其上下文信息来预测每个[MASK]。
该技术可以将语言表征训练看作是一个去噪过程,在去噪过程中,输入的句子能够学习去用一些有噪声的标记进行自我重构。这种去噪训练迫使存在[MASK]的标记利用所有不存在[MASK]的信息,从而产生语境化的表达。
基于Transformer语言模型开发的体系结构设计和掩模训练技术是各种跨模态开发背后的主要原则,这些开发促进了最近VLP模型的激增。图5(b)显示了一个简单的跨模态BERT。与语言训练类似,它对图像进行标记化,并使用一定的技术将图像与语言标记一起嵌入,这些在后面将详细介绍。通常,会将标记化的视觉特征和文本特征一起输入带有掩模语言训练的Transformer编码器,以学习联合表征。
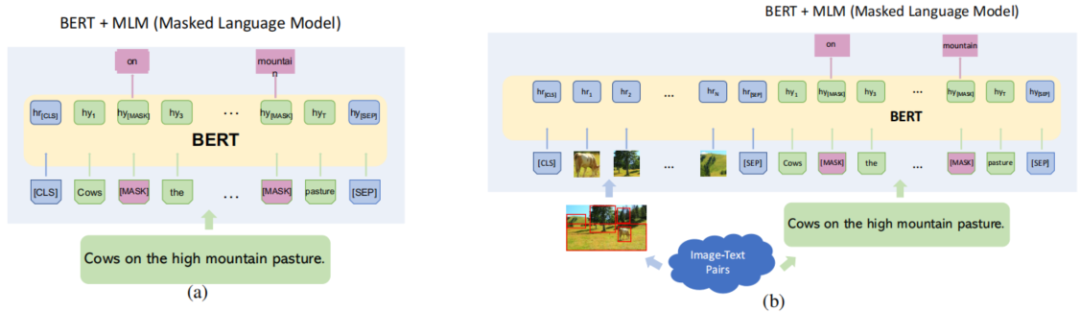
图5 (a)原始的单模态BERT,其中隐藏了一些语言符号进行预测,以训练语言表示。(b)具有多模态的改进BERT,其中图像和语言标记都被输入到一个类似BERT的Transformer模型中。
在本节中,我们将介绍VLP模型的主要组成部分。如图6所示,VLP模型中主要有三大部分,即视觉嵌入(VE)、文本嵌入(TE)和模态融合(MF)模块。VE和TE通常分别用图像和文本进行预训练,而MF则将VE和TE提取的特征,与图像-文本的预训练进行融合。
VLP的目标是学习对象级别语言对齐,语义丰富的视觉表征。对象级别意味着学习后的表征是详细的,并与对象对齐,而不是针对整个图像。使用被检测到物体的特征来表征图像的研究成果是对象级的。语义丰富力求一种能够泛化到广泛语义概念的表征,并且需要从大规模数据集中学习。
在海量数据集上进行预训练对于使用较小数据集的下游任务的性能提升至关重要,因为学习后的表征可以在下游任务中传递。VLP模型已被证明是非常有效的支持下游任务的方法。
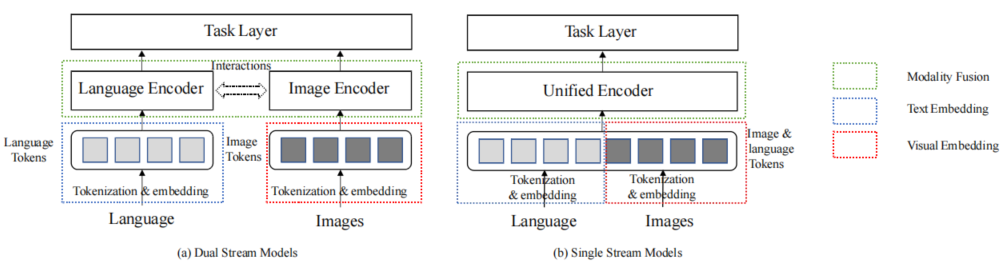
图6 VLP模型的体系结构通常包括视觉嵌入(VE)、文本嵌入(TE)和模态融合(MF)。(a)为双流模型,(b)为单流模型。在双流模型中,模态融合是可选的,由语言和图像编码器之间的交互(通常是交叉注意)完成。在单流模型中,模态融合是在一个统一的编码器(通常是多层变压器)中完成的。
A 为何需要预训练
深度学习本质上是一种统计数据驱动的方法,旨在从已见数据中学习映射函数,以便使用学习到的映射函数对新的数据进行预测。请注意,最终目标是在新的数据上实现良好的性能。在统计学方面,这样的目标被表示为最小化整个数据空间的预期损失,该损失遵循固定但未知的分布。但是,由于分布是未知的,这种预期的损失最小化并不容易处理。
在实践中,必须从该分布中采样数据,并将经验损失定义为预期损失的代替。这听起来可能很奇怪,但实际上是机器学习中常用的做法。例如,对于判断输入图像是否有猫的图像分类问题,最实用的方法是收集有猫和无猫的训练图像,然后通过最小化在该训练集上定义的经验损失来训练分类器。然而,有猫和无猫图像的分布确实是未知的。
统计学习理论表明,对于从足够多未知分布中采样的独立同分布(iid)数据,经验损失最小化结果收敛于预期损失最小化结果。也就是说,渐近地,可以使用iid样本来逼近由未知分布定义的损失函数。然而,在实践中,数据永远不足以代表未知的分布,因此会导致许多缺陷,例如使用新训练集时性能低下、容易受到对抗性攻击等。
预训练允许人们利用无限量无标签(或带有弱标签)的数据来学习符合下游任务的特征。如此大规模的数据集有助于更好的定义预期损失近似值,以便从数据中学习更稳健和真实的规律。由于预训练和微调阶段之间的共享模型,在非常有限(例如,few‑shot)的监督下,微调后学习到的特征被用于下游任务时能够有很高的精度。这使得预训练和微调范式成为解决(或减轻)数据短缺问题的有效方案。
B. 模态嵌入
文本和图像本质上是关于维度和结构的不同级别的信息。为解决这种模态差异,通常使用模态嵌入,即从每个模态中独立提取特征,然后将特征映射到共享特征空间中。如图6所示,模态嵌入涉及视觉嵌入和文本嵌入,两者都包含标记化过程和嵌入过程。视觉嵌入旨在遵循文本嵌入的原理,将图像转换为多个标记,其特征级别为文本标记。Bugliarello 等进行的消融研究证明数据集和超参数的训练是许多不同VLP模型性能改进的主要原因,并且还强调了模态嵌入的重要性。
1)文本标记化和嵌入
在文本嵌入之前,文本应该被标记化。考虑到语言的离散化性质,早期的工作只是将每个单词视为一个标记。一项开创性的研究是Word2Vec,它提出了一个连续的CBOW和一个skip‑gram模型来训练词向量表征。Word2Vec具有良好的计算效率,可以扩展到大型语料库并产生高质量的嵌入。
然而,尽管它的词汇量高达一百万左右,但这种方法由于稀有或未见过的单词而存在词汇量不足的问题,因此难以学习诸如“est”之类的单词子单元。为解决这个问题,Sennrich等人提出了一种子单词标记化的方法,该方法使用字节编码(BPE),将单词分割成更小的单元。子单词标记化被广泛用于包括BERT在内的许多语言模型中。
大多数VLP模型采用来自预训练BERT的文本嵌入。由于BERT是使用Transformer编码器进行掩码学习训练的,因此它具有很强的双向表征能力。
2)视觉标记化和嵌入
与离散并排列在单个维度中的语言标记不同,图像来自高维空间并具有相互关联的像素值。因此,图像标记化通常比文本标记化更为复杂。基本上,图像标记化可以分为基于区域的、基于网格的和基于块的,下面对它们分别介绍。
-
网格特征被卷积特征提取器直接从大小相等的图像网格中提取出来。例如,Huang等人于2021采用网格特征作为其VLP模型的图像嵌入。网格特征的优势主要有两点:第一,方便,因为它不需要预训练的目标检测器。第二个是除了显著目标之外,网格特征还包含可能对下游任务有用的背景。
-
区域特征由预训练的目标检测器提取。最近的VLP模型采用区域特征来学习对象级联表征。特别是,基于BUTD的工作成果,大多数VLP模型采用在Visual Genome(VG)数据集上训练的Faster R‑CNN作为区域特征嵌入。区域特征有三个基本组成部分,分别是边界框、对象标签和RoI特征(RoI池化后的特征向量)。边界框通常在VLP中用作位置指示符,通过变换编码到与RoI特征相同的维度空间并添加到RoI特征中。对象标签在训练方法中被广泛使用,例如Masked Region Classification,这些稍后将在III‑D3中详细阐述。区域特征的优势在于它们帮助VLP模型专注于图像中有意义的区域。这些区域通常与下游任务密切相关。
-
块特征通常通过在均匀分割的图像块上的线性投影来提取。块特征和网格特征之间的主要区别在于,网格特征是从卷积模型的特征图中提取的,而块特征直接利用线性投影。块特征的概念首先由Vision Transformer (ViT) 引入,然后被VLP模型采用。使用块特征的优点是高效。例如,ViLT将预训练速度提高了10倍,是很有竞争力的结果。
图像嵌入方法通常因不同的标记化方案而异。网格特征和区域特征通常来自预训练的卷积模型,而块特征可以简单地通过线性层嵌入。
C. 模态融合
VLP模型的核心是模态融合,它对模态内和模态间融合进行建模,以产生图像和文本的上下文联合表征。MF模式可以分为双流建模和单流建模。VLP的一般结构如图6所示。
1)双流建模:双流建模旨在将视觉和语言映射到相同的语义空间中。它是模态融合的开创性方法。如图6(a)所示,它采用两个独立的编码器分别学习视觉和语言的高级表征。双流设计允许网络深度和架构适应每种模式。除了每种模态内的模态融合外,一些研究还明确设计了两个编码器之间的模态间交互,以实现不同编码阶段的模态融合。
2)单流建模:单流建模旨在学习一种联合表征。图像和文本标记被连接起来并输入到Transformer中,如图6(b)所示。大多数VLP模型都采用这种模态融合方案。单流建模执行隐式的模内和模间融合,不受双流建模中融合阶段的架构设计的限制。
D .训练
为学习视觉和语言的联合表征,视觉语言通常会在大数据集上使用多个自监督学习损失函数对模型进行预训练。目前主要有三种预训练方法,分别是图像文本匹配(Image Text Matching, ITM)、掩膜语言建模(mask Language Modeling, MLM)和掩膜视觉建模(mask Visual Modeling, MVM)。
1)图文匹配:
ITM的目标是预测一对图像和文本是否匹配。ITM可以表述为一个二元分类任务。之前的工作在特殊令牌[CLS]的输出上应用sigmoid函数来预测输入的图像和文本是否匹配。损失函数为:
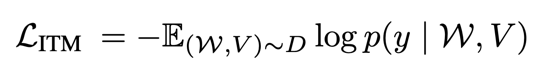
其中 表示一个语言符号序列, 表示视觉内容。或 以表示图像是被匹配 或未被匹配 。
2) 掩膜语言建模:
Chen 等人于2020年利用MLM 激励模型学习语言符号与视觉内容之间的隐含关系。目标是根据已知的语言标记和可视内容重构掩膜语言标记。这个目标可以表述为:
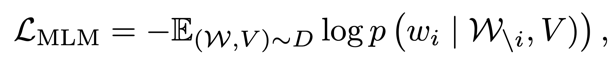
其中表示没有第个单词的句子。请注意,尽管通常采用BPE进行语言分词,但最小的掩码单元是一个完整的单词,而不是一个子单词。这是因为由于信息泄露,可以很容易地从周围的子词中预测出子词。
也有改进版本的MLM。例如,Sun等人于2019年提出了知识掩膜语言模型,该模型执行短语级掩膜和实体级掩膜,将短语和实体级知识集成到语言表征中。对于实体级掩膜,它们将命名的实体视为一个整体。例如,J.K.罗琳(J. K. Rowling) 包含三个符号,是一个人名,应该在实体级掩膜中一起被掩膜。短语级别掩膜将一组词作为一个概念单位。它们掩膜了属于一个短语的所有标记,并同时预测它们。
3) 掩膜视觉建模:
受MLM的启发,MVM被设计用来通过重构被掩膜的视觉内容来学习更符合实际的视觉表示。由于图像的信息密度低于语言的信息密度,MVM比MLM具有更大的挑战性。在重构缺失的单词时,需要对语言进行复杂的理解。
相反,缺失的图像块(patch)可以在不需要跨模态理解的情况下从邻近的patch中恢复。为克服这一差距,大多数工作都是掩盖信息密度相对较高的目标区域。其他工作如SOHO使用视觉字典(VD)来表征视觉领域更全面、更紧凑的语义,因此它们可以像MLM一样应用MVM。综上所述,主要有四种MVM方案。
1) 掩膜区预测(MRP): MRP最小化掩膜区预测出的特征与由经过训练的物体检测器输出之间的距离。
2) 掩膜区域分类(MRC): MRC需要一个模型来预测每个掩蔽区域的对象语义类别。
3) 带KL-divergence的掩膜区域分类(MRC-KL): 由于MRC的目标标签不准确,MRC-KL采用软标签作为监督信号,这是物体探测器在SoftMax后的原始输出。
4) 用可视化字典进行掩膜可视化建模(MVMVD): 与具有词汇字典的语言模型类似,MVMVD需要一个可视化词汇字典(VD)。MVMVD的目标是重构被屏蔽的VD令牌。
有两点值得注意。首先,为了鼓励跨模态融合,一些工作,如UNITERVL,在训练期间每次只屏蔽一个模态的令牌,以鼓励被屏蔽的令牌对另一个模态进行缺失信息的处理。其次,由于相邻的图像网格高度相关,MVMVD倾向于映射到相同的VD令牌; 当执行重构时,模型可以直接复制周围的令牌。
因此,所有映射到相同VD令牌的视觉嵌入向量在SOHO中一起被屏蔽。尽管有上述方法,但有效的视觉建模仍然是一个具有挑战性的问题。一些VLP模型(如SOHO)的消融研究的结果表明,增加MVM任务只会对性能产生微小的额外改善。Cao等人于2020发现,在下游任务中,VLP模型表现出关注文本信息而不是视觉信息的倾向。
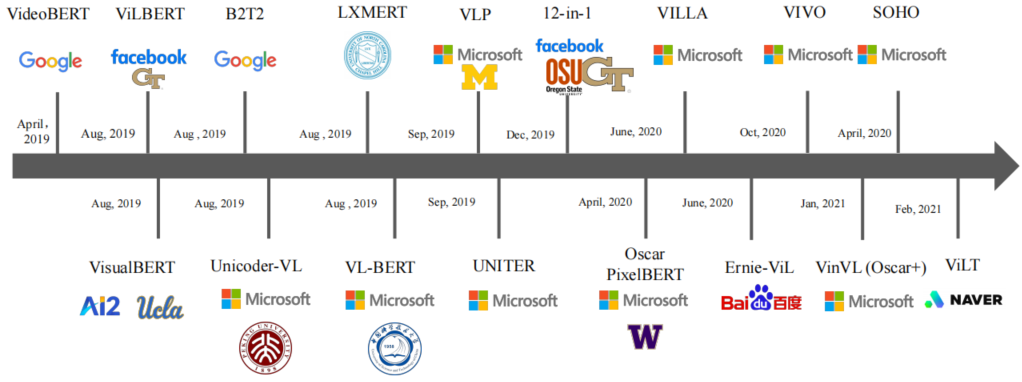
图7 VLP方法的总览。研究成果按公布时间分类。我们还展示了每个作品来自的主要机构的标识。
E. 预训练研究概况
本节在介绍了VLP模型的一般流程之后,总结了跨领域VLP的一些开创性工作。受NLP和CV预训练成功的启发,近年来VLP领域的研究大量涌现,以寻求统一的跨模态表征。VLP研究成果的形势如图7所示。我们在这一节中详细阐述了一些有代表性的研究。
单流模型: VideoBERT是学习视频和语言联合表征的一项开创性工作。其主要思想是将可视的和文本的标记输入到构建在BERT上的单流模型中。文本标记通过自动语音识别方法将视频语音转换为文本来提取,视觉标记通过使用卷积主干从视频片段中提取特征来获取。VideoBERT能够执行广泛的下游分类和生成任务,包括视频说明和零样本掩膜动/名词预测。请注意,VideoBERT是使用烹饪视频进行的预训练,其中的内容是有教学意义且高质量的。它假设口语与视觉内容是一致的,这就限制了它只能应用于某些视频(例如教学型视频)。另一个限制其泛化性的问题是其精心设计的字幕文本模板,例如模板:now let’s [MASK] the [MASK] to the [MASK], and then [MASK] the [MASK],这只适用于烹饪视频。
Li等人提出了一个名为VisualBERT的简易单流VLP模型。提取的视觉和文本标记被直接组合并输入到Transformer中,从而在Transformer里可以隐式地执行跨模态融合。与VisualBERT类似,一些并行研究,如Unicoder VL、VL- bert 和UNITER也采用了单流架构。这些VLP研究在以下几个方面是相似的:1)它们都利用目标检测主干来计算图像嵌入。2)它们都采用掩码语言建模任务。3)均采用单流BERT架构。但它们在预训练的方法和数据集上存在差异。
双流模型: ViLBERT和LXMBERT是将BERT扩展到双流VLP模型的开创性工作。它们在Conceptual Captions数据集上进行预训练,并利用预训练的Faster R-CNN模型来检测区域作为视觉标记。ViLBERT用两个并行流分别处理视觉和文本标记,它们可以在需要时通过跨注意层融合跨模态信息。换句话说,ViLBERT假设了视觉和语言的不同处理架构。它的跨模态融合设计为两个处理流程之间的稀疏和显式融合。LXMBERT与ViLBERT的区别在于解耦模态内和模态间的处理。更具体地说,视觉标记和文本标记在第一阶段被分别编码,然后输入到跨模态编码器以产生联合表征。
其他融合方法: 从根本上说,单流建模和双流建模在融合时间上有所不同,其中单流在早期融合不同的模态,而双流更喜欢在融合前提取每种模态的高级特征。SemVLP提出通过迭代训练来组合这两种流行的建模架构。这种方法利用了这两种架构,并在低级和高级上执行跨模态语义对齐。特别是,Transformer编码器在两种建模方法之间共享,在双流编码器中添加了一个额外的跨模态注意力模块,这有助于语义对齐和减少参数。大多数VLP模型试图将视觉和语言编码为单独的标记,这些标记通过模态融合显式或隐式地相互作用。另一类VLP模型基于目标检测模型将视觉标记附加到文本标记。B2T2提出在文本标记中融合检测到的目标的特征,在此基础上在预训练中执行MLM 和ITM。在B2T2中,标记T可以表示为:
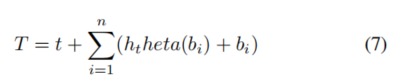
其中t是原始文本嵌入,是标记为的检测到的对象的数量, 是第 个对象的边界框的嵌入,表示从边界框中提取的视觉特征。B2T2还分析了融合对象和文本标记的阶段。结果表明了早期融合的有效性。
弥补模态差距的早期尝试:为实现生成和理解任务,Zhou等人提出了一种统一的视觉语言预训练方法。它引入了两种掩码方案,即双向注意力掩码和序列到序列掩码,以分别增强理解和生成任务。值得注意的是,这种统 一的VLP方法仅在预训练期间采用MLM,并在图像字幕和VQA方面取得了有竞争力的表现。12‑in‑1将多任务训练扩展到四个广泛任务,并在12个数据集上进行预训练。实验结果表明,多任务训练可以持续提高下游任务的性能,并产生参数更少的更轻量级的模型。
VILLA基于UNITER的设计,在嵌入级别将对抗训练引入了视觉和文本标记。它通过在嵌入空间中添加扰动作为正则化来执行对抗性训练,并产生了不错的性能改进。
受ERNIE的知识掩膜方案的启发,结构化知识首先被纳入ERNIE‑ViL的VLP模型中。为了通过构建场景图来开发更好的跨模态语义对齐,ERNIE‑ViL提出了场景图预测任务来对图中的对象、属性和关系进行建模,以学习对象级和属性感知表示。将知识纳入跨模态训练具有挑战性,并且至今仍然是一个悬而未决的问题。
Grid & Patch features:虽然区域特征嵌入的流行促进了VLP模型的训练,但它也限制了VLP模型的可扩展性和泛化能力。经分析,Faster R‑CNN的区域特征的弱点如下所示:
-
类别数量有限:视觉特征受到在具有预定义对象类别的、相对较小的数据集上进行训练的目标检测模型的限制。例如,BUTD中广泛采用的Faster R‑CNN 模型是在VG上训练的,其中有固定的1594 个对象类和524个属性。
-
质量低:由于Faster R‑CNN 模型是在标签良好的小型数据集上训练的,因此区域特征经常受到低质量的影响。
-
缺乏上下文:区域特征在没有任何背景信息的情况下提取属于特定类别的RoI特征,导致忽略了这些区域特征之间的语义关系。实际上,这些语义关系很重要。
PixelBERT试图打破这一限制,通过直接从像素特征中学习来充分利用视觉信息。为了降低计算成本和提高模型的鲁棒性,他没有将所有像素都用作视觉特征,而是在预训练期间随机采样100个像素。然而,实验结果表明,随机采样仅略微提高了性能,在下游任务中的VQA分数低于0.5。
SOHO是另一项利用网格特征进行跨模态理解的开创性工作。为了学习视觉上下文的语义全面表示,SOHO提出了一个学习用于视觉标记化的VD。SOHO是通过首先从卷积网络中获取高级特征来学习VD的,然后根据特征相似性对这些特征进行分组,并馈入移动平均编码器以动态更新VD。
由于视觉嵌入是可训练的,SOHO是一个端到端的预训练框架,可以直接从像素中学习,无需边界框。通过训练过程中的动态VD更新,VD中每个标记的序列号可以像语言标记一样被视为一个标签,从而可以很自然地执行掩码视觉建模。对于预训练任务,SOHO提出了一种新颖的MVMVD方法(在III‑D3中描述)来同时掩盖图像中同一标签的所有视觉标记,以避免任何信息泄漏。
上述基于区域或网格的图像嵌入计算量很大,提取的高级特征阻止了跨模态信息的早期融合。受ViT的启发,ViLT采用图像块的简单线性投影作为视觉嵌入,将预训练速度加快了10倍,并且实验结果具有竞争力。这意味着,相比于视觉嵌入,模态融合更可能是改进VLP模型表征的关键。
改进对齐表示:视觉语言对齐表示是VLP的基本目标。为了实现这一目标,一些研究提出可以在VLP中采用额外的对象级数据。例如,许多VLP方法采用了RoI区域特征和检测模型。然而,作为重要组成部分的检测到的对象标签并未在VLP模型中被明确建模。为了利用这些附加信息,Oscar引入了对象标签作为锚点,以帮助学习跨模态对齐的表征。这种学习过程在经验上是自然的,因为检测到的对象标签经常出现在和图像配对的文本中,这有助于对齐视觉和语言。
此外,使用对象标签进行训练有助于学习对象的共现(例如,和对象单词会共同出现的单词)。因此,Oscar在下游理解和生成任务上产生了显著的改进。然而,Oscar 的缺点也很明显,它依赖于标记良好的图像字幕数据集,因此难以扩大训练规模。
由于VLP模型受到不充分对齐的(图像、字幕)对的限制,VIVO建议使用大量的(图像、标签)对来增加预训练的程度。VIVO采用Hungarian匹配损失进行掩码标签预测,这使得它可以进行视觉词汇学习,提高模型描述下游任务中的新对象的泛化能力。它在NoCaps基准测试中首次超过了人类的表现。更具体地说,它采用ResNeXt152‑C4并合并了包括VG、COCO、Objects365和 OpenImagesV5的四个公共数据集用于大规模训练。 相比于VIVO和Oscar等VLP模型,VinVL有了显著改进,并在NoCaps、图像字幕和VQA排行榜上取得了最佳成绩。
4
扩大模型和数据规模
尽管研究者已经在视觉语言联合表示方面取得了令人鼓舞的进展,但上述大多数研究主要集中在追求良好的跨模态对齐的对象级表示上。而且他们采取了一个门槛较高的假设:假设图像和文本对被很好地标记。这项假设将训练数据集限制为相对较小的拥有“黄金标签”的数据集。例如,Conceptual Captions是广泛用于VL预训练的最大公共数据集,它具有300万个图像‑文本对。
为了使模型获得更丰富的语义和更强的泛化能力,研究者非常需要更大的弱标记数据集,例如网络爬虫数据集。CLIP和DALL‑E将大规模网络爬取数据用于预训练的第一个成功实践案例。受CLIP和DALL‑E成功的启发,最近有几项研究工作进一步构建了基于更大数据集的更强大的模型。
本节旨在介绍使用大规模弱标签数据集训练的模型。本节分为两部分。第一部分包括利用大规模数据集进行视觉理解的工作,例如CLIP、ALIGN、SimVLM和Florence。第二部分包含基于诸如DALL‑E、GODIVA、NUWA等大型数据集的视觉生成模型。
A. 视觉理解
CLIP中的核心思想是训练方法。CLIP不像其他VLP方法那样通过训练去预测掩模的视觉或文本标记,而是学习识别成对的图像和文本。CLIP的目标是:在给定一批数量为N的(图像‑文本)对时,CLIP应能够预测N × N个可能出现的对中哪些是匹配对(正样本),哪些是非匹配对(负样本)。经过预训练后,CLIP可以通过使用类似于“a photo of”等短语加上类别名称作为提示来告诉模型输入图像与哪些类别最相似,从而执行零样本图像分类。与全监督的基线相比,零样本CLIP在27个数据集中的16个数据集上优于基线。
与CLIP类似,ALIGN也采用了具有对比损失的双编码器模型执行零样本任务。它利用了一个更大的原始数据集,包含1.8B图像‑文本对。ALIGN在许多零样本视觉任务上的表现优于CLIP,这证明用更大的数据集训练会带来更好的性能。
除了视觉任务,ALIGN在图像文本检索任务上的表现也优于之前的工作成果。SimVLM开发了一种新的VL预训练方法。它遵循一个简单的前缀语言建模目标,以自回归的方式预测下一个标记。它在多个VL任务上取得了有竞争力的结果,并具有文本引导的零样本学习能力。与之前采用粗略(图像级)表征和静态(图像)数据的工作不同,Florence采用细粒度(对象级)表征并扩展到了动态(视频)数据。对于对象级表示,研究者将适配器Dynamic Head添加到了Florence中的图像编码器并使用额外的对象检测数据集进行训练。通过对9亿对的图像‑文本对的预训练,Florence在44个具有代表性的基准中的大多数中取得了新的最先进的结果。
除了零样本分类,CLIP还可以帮助检测。例如,ViLD提出了一种通过CLIP蒸馏的零样本检测器。其他研究表明,CLIP 可以学习那些更像来自人脑中的神经元的多模态特征,并且它还可以帮助完成VL任务。
B. 视觉生成
除了视觉理解,大规模弱标记的图文配对数据也可以辅助文本到图像的生成。Ramesh等人(2021)开发了一种名为DALL‑E的图像生成系统。DALL‑E使用离散变分自动编码器(dVAE)将图像转换为离散的视觉标记,以便将一个(文本、图像)对视为单个数据流。
在训练期间,文本图像流被送到仅为解码器的Transformer中。在其中应用注意力掩码时,每个图像标记都可以看到所有的文本标记。文本标记之间的注意力掩码是标准因果掩码。图像到图像的注意力使用行、列或卷积注意力掩码。在推理时,给定文本标记,生成过程是像在GPT中一样以自回归方式预测图像标记。DALL‑E在四个方面展示了令人印象深刻的结果:创建动物和物体的拟人化版本、组合不相关的概念、渲染文本以及对现有图像应用转换。
受DALL‑E训练方法的启发,Wu 等人(2021a)提出了一种名为GODIVA的方法来从文本中生成视频。与DALL‑E类似,GODIVA对视频的每一帧进行标记,并将文本和视觉标记顺序连接为流来训练模型。DALL‑E和GODIVA分别设计用于文本到图像的生成和文本到视频的生成,而Wu等人(2021b)提出了一个统一的视觉生成模型,该模型在文本到图像、文本到视频、视频预测等8个下游任务上取得了最先进的结果。
他们提出了一个能够编码的3D Transformer,它能够对所有三种数据格式进行编码,包括文本(1D)、图像(2D)和视频(3D)。为了优化视频的效果,他们还设计了一个3D Nearby Attention来沿空间和时间轴应用注意力。
5
未来趋势
在过去几年中,我们见证了VLP模型如何逐渐使用大量弱标记和更多样化的数据。未来,模型和数据的规模都将不断扩大,从而实现更强的模态合作,甚至是统一表征。此外,结合知识可以进一步增强VLP模型,从而使其获得更好的泛化能力。在本节中,我们将讨论这些未来趋势。
A. 走向模态合作
除了使用VL数据集改进跨模态任务外,模态合作技术正逐渐在预训练中被使用,从而提高单模态任务和多模态任务的性能。模态合作就是不同的模态互相帮助,以学习更好的表征。例如,用视觉数据改进语言任务,用单模态数据改进跨模态任务。
-
利用视觉数据改进语言任务
研究者已经尝试过利用视觉信息改进语言学习,并在广泛的语言任务上进行了探索,其中包括机器翻译、语义解析和语言基础等任务。这些研究探索是为特定的语言任务量身定制的,并且这些研究成果之间可能存在模态差异。
Tan和Bansal(2020年)提出了一种带有视觉辅助的语言表示的通用预训练模型,其中引入了“vokenization”模型,以将视觉语言对齐从图像说明数据集外推到纯语言语料库。更具体地说,使用图像文本匹配对“vokenization”模型进行训练,以构建视觉图像词汇表,然后利用该词汇表将仅语言数据集中的文本标记映射到检索到的得分最高的图像。实验结果表明,它的性能相比自监督语言模型有了额外的进步。
2. 使用单模态数据改进跨模态任务
为了解决数据短缺问题,一些VLP模型利用额外的单模态数据来提高表示能力。例如,在图像‑文本数据集中,文本通常很短,只带有几个标记,这限制了文本的表征能力。因此,研究者在VL‑BERT中添加了额外的语言语料库来改进跨模态任务中的语言部分。
B. 走向通用统一模态
由于Transformer架构,研究人员在单模态和多模态表征学习方面都取得了显著进展。在前面的部分中,我们讨论了多模态表征和模态合作,它们以不同的方式连接视觉和语言。目前,该领域内的一个更大的目标是建立一个可以统一多种模态的通用表示模型。
在一项开创性的工作UNIMO中,一个统一的预训练模型被提出,它可以同时处理单模态和多模态的下游任务,包括理解和生成。它使用了大量单模态和跨模态数据进行预训练,包括BookWiki(Zhu et al., 2015)和OpenWebText(语言数据)、OpenImages(Krasin et al., 2017)和COCO (Lin et al., 2014)(图像数据)、COCO(Lin et al., 2014)、Visual Genome(Krishna et al., 2016) 、Conceptual Captions(Sharma et al., 2018)和SBU(Ordonez et al., 2011)(图文数据)。
因此,UNIMO在执行许多单模态和多模态下游任务时的性能得到了大幅改进。另一个有趣的研究成果是Gupta等人开发的通用视觉系统,它可以用于一系列视觉和跨模态任务。
C. VL+知识
模型在执行VL任务时,会有许多任务需要依靠超出训练数据集的常识和事实信息才能够完成。但是,大多数VLP模型没有消耗额外知识的机制。
ERNIE提出了一种基于知识的多阶段掩模策略。该方法没有直接添加知识嵌入,而是将语言掩蔽在三个级别,即基础级别、短语级别和实体级别。对于实体级屏蔽,模型会屏蔽整个实体而非子单词。此类实体包括人员、位置、组织、产品等。还有一种将知识集成到VLP模型中的方法。
Shevchenko等人(2021)提出将知识嵌入直接注入视觉语言Transformer中。他们首先使用知识嵌入构建知识库(KB),然后将训练数据中的句子与知识嵌入进行匹配。在训练期间,他们使用辅助损失来促使已学习到的表征与知识嵌入保持一致。尽管已经有一些研究工作试图将知识整合到VLP模型中,但为了完成该目标,仍有许多挑战需要解决,例如如何有效利用具有高噪音的大型维基数据以及如何以可解释的方式从知识中学习。

雷峰网(公众号:雷峰网)
雷峰网版权文章,未经授权禁止转载。详情见转载须知。