大模型“研究源”告急:研究预测,2026年高质量语言数据将耗尽
导语:数据存量的增速远低于大模型训练数据集规模的增速。
数据存量的增速远低于大模型训练数据集规模的增速。
作者 | 李梅
编辑 | 陈彩娴
语言模型的缩放定律(Scaling law)表明,其规模大小取决于可用数据的数量,所以在过去几年,大约有一半的语言模型是通过扩大数据量来改进性能的。
当前,在参数量上的角逐似乎已进入冷静期,然而,当许多人还在讨论模型要不要继续做大的时候,模型能不能做大的问题已经出现了。
最近,一项来自 Epoch AI Research 团队的研究向我们抛出了一个残酷的事实:模型还要继续做大,数据却不够用了。
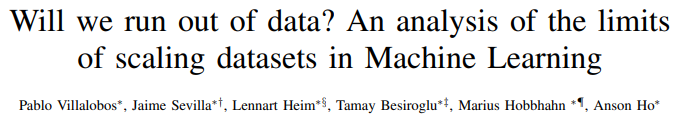
论文地址:https://arxiv.org/pdf/2211.04325.pdf
研究人员预测了 2022 年至 2100 年间可用的图像和语言数据总量,并据此估计了未来大模型训练数据集规模的增长趋势。
结果表明:高质量的语言数据存量将在 2026 年耗尽,低质量的语言数据和图像数据的存量将分别在 2030 年至 2050 年、2030 年至 2060 年枯竭。
这意味着,如果数据效率没有显著提高或有新的数据源可用,那么到 2040 年,模型的规模增长将放缓。
对数据端的建设该重视起来了。
1
数据存量是大模型数据集的规模上限
数据存量预测
数据量的多少会限制大模型训练数据集的规模大小,所以要先对数据存量的增长趋势进行预测。
在预测未来语言和图像数据存量方面,研究团队开发了概率模型来预测数据累积率。
近年来无监督学习在基础模型领域大为成功,它允许我们使用少量标注数据和大量未标注数据、针对多项任务进行微调,无监督模型也被证明能够为未标注数据生成有价值的伪标签。所以,这里主要关注未标注数据的存量和累计率。
另外,要预测数据累积率,得先确定哪些因素会导致数据的增长。绝大多数数据是用户生成的,存储于社交媒体平台、博客、论坛中。所以决定某一时期产生多少数据的因素有三个:人口数量、互联网普及率和每个互联网用户产生的平均数据量。研究团队据此开发了一个用户生成内容累积率的模型。
训练数据集规模增长预测
在数据存量的预测基础上,研究人员进一步估测了未来大模型的训练数据集规模的增长趋势。
数据集规模(dataset size)在这里被定义为训练模型所依据的独特数据点(datapoint)的数量。不同领域对数据点的定义不同,对于语言数据而言,数据点即一个词,图像数据则定义为一张图像。
如果根据数据集规模的历史变化来预测未来的趋势,那结果会是“未来会继续延续历史”,这当然不够准确,因为实际上可训练模型的数据量是有限制的,最大的限制之一就是计算可用性(compute availability)。要对已有模型增加训练数据量,当然需要更多额外的计算,而计算会受到硬件供应以及购买、租用硬件的成本的制约。
所以,预测数据集规模时要将计算可用性的限制考虑进去,为此作者团队也根据计算可用性和计算优化(compute-optimal)的数据集规模做了预测。
关于模型的规模增长,有一个重要概念是 Scaling law(缩放定律),Scaling law 可用来预测给定计算预算(以 FLOP 衡量)下的模型规模和数据集规模之间的最优平衡。具体来说,最优的数据集规模与计算预算的平方根成正比。这项工作便预测了未来每年将会达到的最优训练数据集规模。
2
语言数据将耗尽于 2026年
先来看语言模型。
语言数据的质量有好坏,互联网用户生成的语言数据质量往往低于书籍、科学论文等更专业的语言数据,在后一种数据上训练的模型性能也更好。所以,有必要区分开来,为了获得更全面的结果,作者分别对低质量语言数据和高质量语言和数据的存量进行了估测,我们来看看结果。
对低质量语言数据的当前总存量进行估测,得到存量为 6.85e13 到 7.13e16 个单词。如下图。
其中,区间上的1e14 很可能是代表对于资金雄厚的大公司如谷歌可用的语言数据存量;1e15 是对于所有科技公司可用的量;1e16 则是全球人类多年间集体产生的量。当前每年语言数据增长率在 6.41% 到 17.49% 之间。
图注:低质量语言数据存量
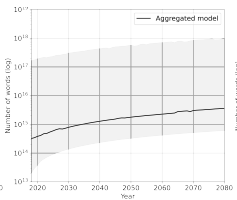
接着,以这里的低质量语言数据存量作为数据集的规模上限来进行预测,结果发现,语言数据集规模会先经历快速增长直到数据存量耗尽,之后增长速度会大幅放缓。如下图,数据存量耗尽的时间节点在 2030 年之后。
图注:低质量语言数据集规模增长趋势
在高质量语言数据方面,作者估测了数字化书籍、公共 GitHub 存储库和科学论文中可用文本的全部数量,并假设其占高质量数据集的 30 %-50%,从而预测出当前高质量语言数据的总存量为 9e12 [4.6e12; 1.7e13] 个单词,每年增长率为 4% 到 5%。如下图。
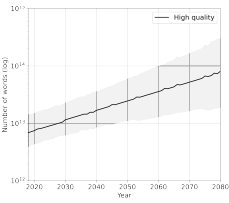
图注:高质量语言数据存量
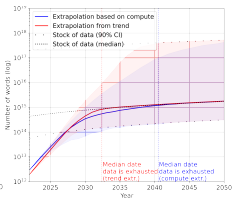
这时,以高质量语言数据存量作为数据集规模上限,发现了相同的数据集规模放缓模式,但放缓会发生得更早,在 2026 年之前。如下图。
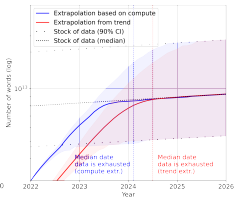
图注:高质量语言数据集规模增长趋势
再来看视觉模型。
对于视觉模型来说,什么样的图像数据算是高质量数据,这方面我们目前还了解不多,所以作者这里未区分高低质量。
经估测,作者发现,当今互联网上的图像总存量在 8.11e12 和 2.3e13 之间,年增长率约为 8 %。如下图。
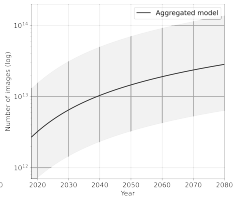
图注:图像数据存量
以这一存量作为图像数据集规模的上限,根据历史趋势和计算最优来预测训练数据集规模的增长,发现与语言模型类似,图像数据集的规模会呈指数增长,直到图像数据存量耗尽,之后增长率会下降。如下图。
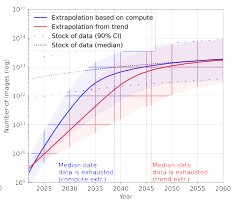
图注:图像数据集规模增长趋势
作者进一步计算了每种数据集规模每年会遭遇数据存量耗尽的概率,包括两种预测,一是根据历史趋势的预测,二是根据计算可用性的预测。结果如下图。
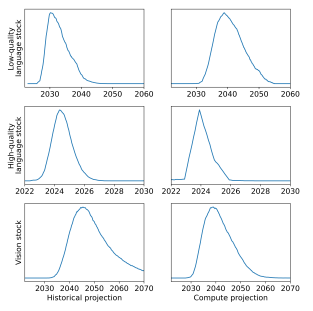
图注:低质量语言数据存量、高质量语言数据存量和视觉数据存量每年发生耗尽的概率
对于语言模型而言,数据的枯竭将会在 2030 年到 2040 年之间到来;对视觉模型而言,则是 2030 年到 2060 年之间。
具体来说,低质量语言数据和视觉数据枯竭的日期存在较大的不确定性,但基本上不太可能发生在 2030 年之前或 2060 年之后。但高质量的语言数据几乎肯定会在 2027 年之前耗尽。
3
大模型的数据瓶颈如何破除?
上述研究结果表明,数据存量的增长速度远低于训练数据集规模的增长速度,所以如果当下的趋势继续下去,我们的数据库存一定会耗尽。而且,高质量的数据会更少。
或许更大的数据集能够替代较低质量的数据集,但即使如此,数据集规模增长的放缓是不可避免的,因为扩大数据集同时也会受到计算可用性的制约。
如果这项工作的预测是正确的,那么毫无疑问数据将成为做模型继续做大的主要制约因素,AI 的进展也会随着数据量的耗尽而放缓。
但大模型毕竟是数据驱动的。阿里巴巴达摩院基础视觉团队负责人赵德丽博士曾告诉 AI 科技评论,数据侧的建设将会成为每一个做大模型工作的机构必须要考虑的问题,大模型有多少能力,往往取决于你有什么样的数据。
举个例子,赵德丽博士在从事生成模型的研究中发现,与文生图大模型相比,做文生视频大模型要难得多,原因就在于视频数据的数量远比不上文本和图像,更不要谈数据的质量了。相应地,目前已有的文生视频模型的效果都不尽如人意。
不过,事情或许还没那么糟。
这项工作的作者承认,当前的预测结果更多是基于理想条件下的假设,即目前的数据使用和生产的趋势将保持不变,且数据效率不会有大的改进。
但是,如果未来数据效率得到提高,大模型有可能并不需要更多数据就能实现同等的性能;
如果目前看来正确的 Scaling law 被证明为错误,那也就是说在数据很少的情况下,即使数据效率没有提高,也会有其他更好的扩大模型规模的办法;
如果通过迁移学习,多模态模型被证明比单模型模型性能更好,那么也可以增加数据存量从而扩大各种数据模态存量的组合;
就数据存量本身,如果对数据进行组合使用,甚至可以无限增加数据存量;如果社会经济方面发生重大转变,也可能会产生更多新的数据种类,例如等到自动驾驶汽车大规模普及,那么道路视频的记录数据将会大大增加。
以上这些“如果”或许正是大模型的未来所在。
更多内容,点击下方关注:
扫码添加 AI 科技评论 微信号,投稿&进群:

未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。
雷峰网(公众号:雷峰网)
雷峰网版权文章,未经授权禁止转载。详情见转载须知。