英特尔为中国公司定制了一张AI大模型「入场券」
导语:一款AI芯片,英特尔为什么发布了两次?
一款名叫Gaudi2的AI芯片,2022年和2023年英特尔都为其开了一场发布会,为什么?
有两个方面的原因,一个在当前国际形势下的合规之举,另一个在生成式AI热潮下亮出的入场券。

这里的入场券有两层含义,一层含义是对正在四处寻找合适芯片的AI大模型算法公司来说,英特尔的Gaudi2能够成为这些公司发展业务的算力基石,足够的算力大模型竞赛的入场券。
另一层含义是对于英特尔来说,拿出的能和英伟达最先进的H100 GPU比拼的产品,是其在AI大市场里披荆斩棘的入场券,也是一个“大杀器”。
站在AI的变革时刻,手握AI时代入场券的公司,如何才能成为AI时代的领导者?
英特尔有一个十分清晰的路线图,2025年将会推出更适合AI需求的芯片,新的产品将融合Gaudi和GPU。
Gaudi2再次发布的2个原因
2022年的英特尔On产业峰会上,英特尔发布了新一代高性能深度学习AI训练处理器Habana Gaudi2,那时的Gaudi2训练BERT模型的性能相比英伟达A100就有2倍的性能优势,广受关注。
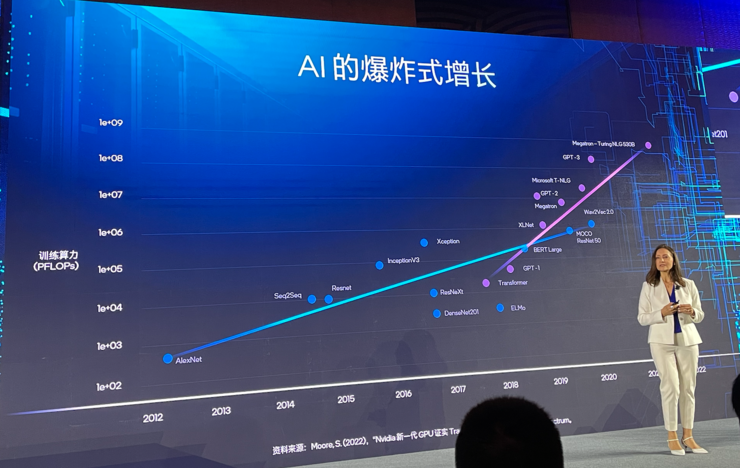
2023年7月,英特尔在北京又举行了一次Gaudi2的发布会,原因有两个。
“过去5个月大模型的演进非常快,去年发布audi2之后,我们做了大量软件模型的优化工作,可为大规模的多模态和语言模型提供出色的推理性能。”英特尔公司执行副总裁,数据中心与人工智能事业部总经理Sandra Rivera说,“这次我们不只是带来了一颗芯片,还带来了基于Gaudi2可以大规模部署训练以及推理大模型的整体解决方案。”
为了市场需求再次发布是一个原因,另一个原因是因为政策。
“这次在中国发布的Gaudi2,是中国定制版产品,对于出口或支持中国的客户没有任何问题。”Sandra分享。
中国版Gaudi2和国际版最大的区别是网口的数量,国际版集成以太网端口数量是24个,中国版减少到了21个,这一变化会降低中国版Gadudi2网络速度,对整体的性能影响不大。

这其实是在满足互联总线带宽不能超过400GB/s的美国出口法规限制。雷峰网了解到,在法规的限制下,下一代Gaudi3在中国市场销售的版本也会和国际版有所不同。
用性价比和英伟达掰手腕
英特尔发布中国版Gaudi2并积极宣传的目的非常明确——从英伟达手上分一杯羹。
生成式AI火热之后,英伟达次新的A100和最新和H100 GPU在全球都成为了紧俏商品。在中国这种情况更加严重,并且因为有美国法规的限制,A100和H100并不能直接向中国市场出售,只能销售互联带宽更低的A800和H800。
这给包括英特尔在内的所有高性能AI加速芯片的提供者一个绝佳的机会,能从英伟达手里分一杯羹,就意味着抓住了AI这个未来十年甚至更长时间的大市场。
Gaudi2非常聪明地从性价比的角度与当下最强大的H100和A100竞争,这种聪明更直白的说就是抓住了用户最急切的需求。
“A100的定价相比此前的产品已经偏贵,到H100时定价已经贵的有些夸张,加上供货紧缺带来的价格上涨,H100让大量公司都对替代产品更有兴趣。”多位AI行业从业者都对雷峰网表示,“只要其它AI芯片的性能和体验达到英伟达的80%,价格是英伟达的一半,就一定有客户愿意买单。”

性价比可以借用数据直观体现。最受欢迎的AI开源模型提供商Hugging Face分享性能结果显示,Gaudi2在多种训练和推理基准测试中表现出的超过英伟达 A100 GPU的性能。在训练计算机视觉模型时,Gaudi2的每瓦性能是A100的2倍,对于1760亿参数的BLOOMZ推理,Gaudi2的每瓦性能是A100的60%,有全方位的能效比优势。

再看AI领域权威的基准测试MLPerf在六月发布的最新结果。
Gaudi2和英伟达H100是唯二提交GPT-3模型训练结果的半导体解决方案。结果显示,Gaudi2在384个加速器上训练GPT-3的时间为311分钟,英伟达在512个H100 GPU上的训练时间则为64分钟。

“这意味着,基于GPT-3模型,每个H100的性能领先于Gaudi2 3.6倍。”Habana Labs首席运营官Eitan Medina直言,“性价比是影响H100和Gaudi2相对价值的一个重要考量因素。Gaudi2服务器的成本要比H100低得多,所以Gaudi2的价格优势能够大大缩小了与H100的性价比差距。”


谈性价比,不能绕开软件,也就是使用体验。
几分钟就能迁移代码,Gaudi2高度适配大模型
芯片的使用体验,对于有开发经验的工程师来说是迁移的,对于没有代码的工程师来说是上手的难度。
Hugging Face 的首席布道者Julien Simon分享他使用Gaudi的经历,“在我第一次使用时,只花了10分钟,其中还包括阅读文档。在运行了我的加速脚本后,它立即就可以工作。我必须说这是我见过的最简单的开发体验之一,如果你有现成的代码,可以在几分钟内进行迁移。”
几分钟就能迁移原有模型的开发体验来源于英特尔针对Gaudi平台深度学习训练和推理优化的SynapseAI软件套件。这一软件套件集成PyTorch、TensorFlow、DeepSpeed框架,也支持Kubernetes编排,定制编译器。

同时,SynapseAI软件套件也有强大的合作伙伴生态系统,包括Hugging Face、PyTorch Lightning、RedHat。其中,超过5万个模型在Hugging Face平台上使用Optimum Habana软件库进行了优化。
这让Gaudi2对大模型开发者非常友好,从github上也能看到Optimum Habana对大量大模型支持的情况。像是对Stable Diffusion(一个用于从文本生成图像的最先进生成式AI模型之一)训练,Gaudi2能够实现从1张卡至64张卡近线性99%的扩展性。
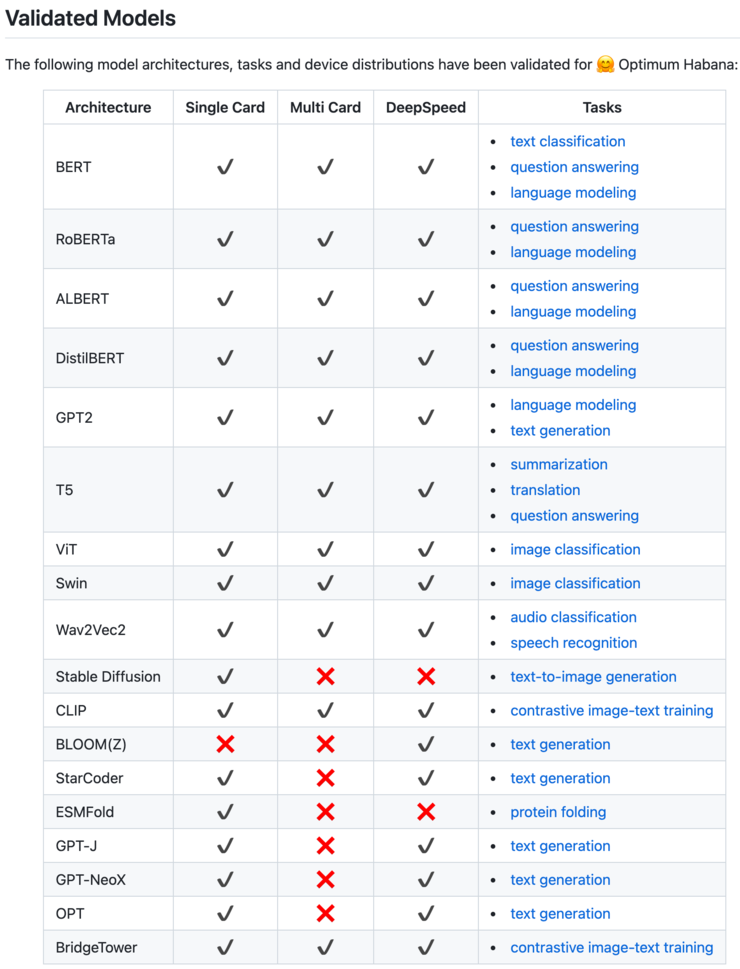
随着软件优化的持续深入,开发者能够拥有更好的开发体验。而与Hugging Face的合作,也让开发者不用考虑英伟达的CUDA软件生态。
“确实很多人在用CUDA进行人工智能运算,但是大模型的开发者,大部分不会做那么底层的开发的,他们是在一个比较高的框架,比如PyTorch、TensorFlow上面做创新。”Sandra十分有信心,“我们和Hugging Face做了一些对策和合作,一些现有模型只花几十秒的时间就可以调通,能够运行在Gaudi上。”
“Gaudi2之前已经有一代产品,我们做了好几年积累,底层软件库都已经开发好。”Eitan补充,“我们希望让开发者能够在最上层的20%做他的开发,这里的开发和CUDA没有那么直接的关联。”
目前,浪潮信息已经发售基于Gaudi2深度学习加速器的浪潮信息AI服务器NF5698G7,这款服务器集成了8颗Gaudi2加速卡HL-225B,还包含双路第四代英特尔至强可扩展处理器。
英特尔也会打造基于Gaudi2的大规模集群,作为英特尔开发者云的一部分向中国客户提供。
2025年有更整合的GPU
Gaudi2是英特尔在大模型热潮里拿出的算力武器,但对于生成式AI的需求显然还不足够。
“明年我们会发布下一代产品Gaudi 3。”Sandra还透露,“2025年时,我们会把Gaudi的AI芯片与GPU路线图合二为一,推出一个更整合的GPU的产品。”
混合DSA(领域专用架构)是AI芯片领域明确的趋势,将Gaudi和GPU整合,既能发挥DSA的性能和能效优势,又能拥有GPU的通用性,这是高性能AI芯片公司都在努力的方向,但软件是一个挑战。
“从开发者的角度,他们更看重的是可持续的软件生态。”Sandra非常清楚,“在迭代产品的同时,我们要对开发者做最好的软件支持,让他们投入软件的一些代码能够在迭代的时候可以更好复用。”
当然,除了朝混合DSA的方向努力,英特尔还有丰富的AI产品组合的优势,包括CPU、GPU、FPGA和DSA。

Sandra对雷峰网(公众号:雷峰网)表示,“很多数据中心的客户有成百上千个至强,他们可以很方便的在现有的数据中心上用至强做一些简单的推理工作。对于千亿级参数的模型训练,需要像Gaudi这样在性能、性价比或者是在供电上都是有平衡考量的产品。GPU Max在科学计算领域可以提供更高的性能和性价比。”
百度智能云服务器高级经理何永占就分享了其使用至强的经验,集成英特尔AMX加速引擎的第四代英特尔至强可扩展处理器为ERNIE-Tiny模型带来了多倍的性能优化。
显然,英特尔在生成式AI热潮里已经交出了不错的答卷,接下来就要看其能在AI大市场里俘获多少客户的心。
雷峰网原创文章,未经授权禁止转载。详情见转载须知。